 發表
發表


 我的網誌
我的網誌
(圖片來源:shutterstock)
人工智能是未來趨勢
隨著人工智能科技蓬勃發展
已逐漸改變人類生活
過往駕駛需專心在路況上
但現在可透過車中的攝影鏡頭
將影像傳至電腦的程式中進行運算
判斷路況的安全性,近而做出相對應的反應
甚至連機器人在某些事情上已正式超越人類
如 AlphaGo 在圍棋領域戰勝許多世界的棋王
使人工智能再度贏得被全球關注
作者將 AI 產業文分成上下兩篇
本文將進行人工智能的簡介、歷程和演算法介紹
下一篇將著重在人工智能的應用及相關之類股
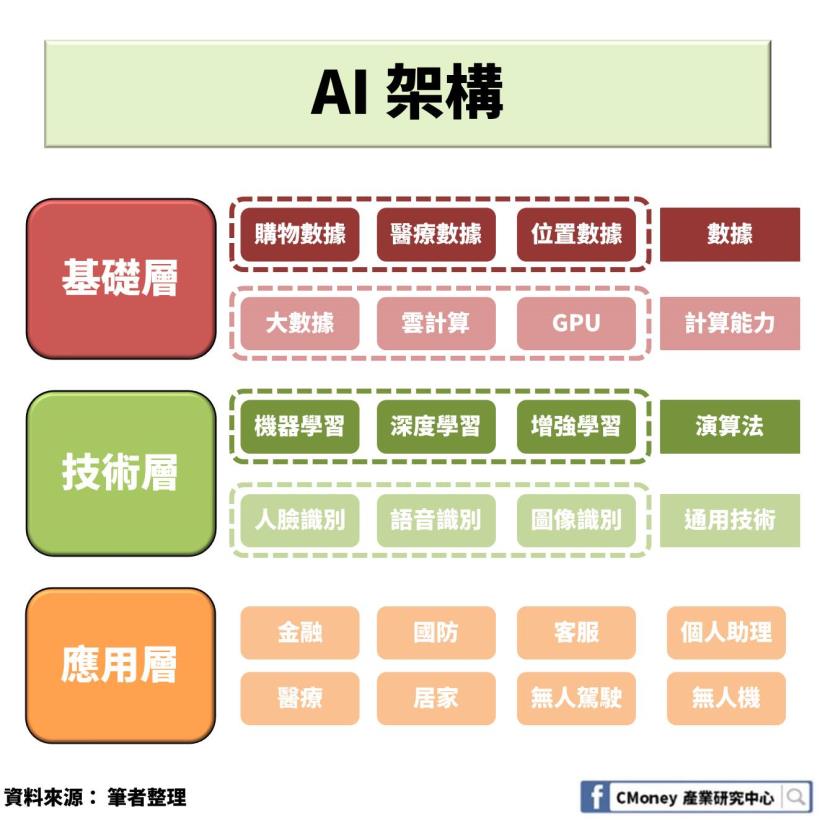
人工智能簡介
人工智能(Artificial Intelligence,AI)
指由人類創造出來的機器所展現的智能
試圖透過計算來模擬人類的思維過程和行為
AI 的目標是模擬人類大腦
並利用電腦的眼睛(攝影機)、耳朵(麥克風)、
嘴巴(喇叭)、手腳與身體(機器人)
取得外在世界的資訊
根據這些資訊進行類似人類的智慧行為
像是影像辨識、手寫辨識、語音辨識、機器人控制等
都是典型的 AI 領域
當然還有許多與感官無關的領域
像是電腦下棋、自然語言理解、機器翻譯、知識工程等等
這些都是與大腦功能直接相關的領域
也是AI 領域當中的經典學問
人工智能歷程
提到人工智能,一定不能遺忘這位人物—Alan Turing
被譽為計算機科學與人工智能之父
最早提出著名的「圖靈測試」理論
強調機器能透過模仿學習產生思考
為人工智能提出初步的定義
假設機器能夠與人類展開對話(透過電子傳播設備)
而不被辨別出其機器的身份
那麼這台機器就具有智能的功效
深入了解人工智能前
一定要先了解人工智能過去的歷史
人工智能的出現可追朔至 1950 年
經歷過三次熱潮
第一次熱潮(1956-1974):演算法雛形的生成
第一次熱潮主要成就是演算法雛形的生成和早期人工智能系統
其中最為傑出的演算法代表是
貝爾曼公式(強化學習的雛形)和感知機(深度學習的雛形)
早期人工智能系統是利用電腦針對特定問題進行搜尋與推論並給予解決
效果最好的就是自動化定理證明
但隨著計算能力的不足、社會資源的撤資和政府補助的下降
使人工智能迎來第一次的寒冬
第二次熱潮(1974-2006):專業化發展
較第一次熱潮而言,第二次熱潮更倚重各領域專家的知識
把大量專家的知識輸入電腦中
電腦依照使用者的問題判斷答案
這一時期主要有人工智能計算機、多層神經網絡和反向傳播演算法等出現
首度突破語音識別及語言翻譯領域
由於人工智能應用依然有限
人工智能便在 90 年代逐漸消退
第三次熱潮(2006-至今):互聯網大數據的機器學習
與前兩次較為不同
由於晶片技術的進步提升運算能力
加上晶片成本的下降,使用雲端儲存變得便宜
在雲端伺服器內收集了世界各地的大數據
使第三次熱潮依然延續至今
其核心領域為機器學習和深度學習
2016 年的 AlphaGo 靠著強化學習勝出世界各地棋王
使人工智能逐漸成為現今炙手可熱的研究領域
機器學習在語音識別、圖像識別、自然語言理解等領域
均取得突破性發展
再加上大量的數據樣本和強大計算能力的硬體加持下
人工智能高速發展
人工智能進化的差異
現今的機器學習與早期人工智能系統有 4 種根本性的差異
1.在大數據時代,機器學習方法需要大量的資料提升預測準確率
2.資料的採集、篩選以及處理,顯得挑選變數相當重要,攸關於模型的建立好與壞
3.機器學習的模型建立於統計關係,而非早期人工智能系統建立在邏輯與語義關係
4.機器學習結果的意義來自於設計者賦予的意義,而非模型結構本身
演算法介紹
自 AlphaGo 打敗世界各地棋王後
人工智能近年得到大量的關注
AI 領域主要包含電腦視覺、機器學習、自然語言處理、語音識別、機器人等等
但在深度學習及電腦視覺上較有突破性的發展
其中深度學習是機器學習的進階
以下分別探討機器學習當今主流的演算法
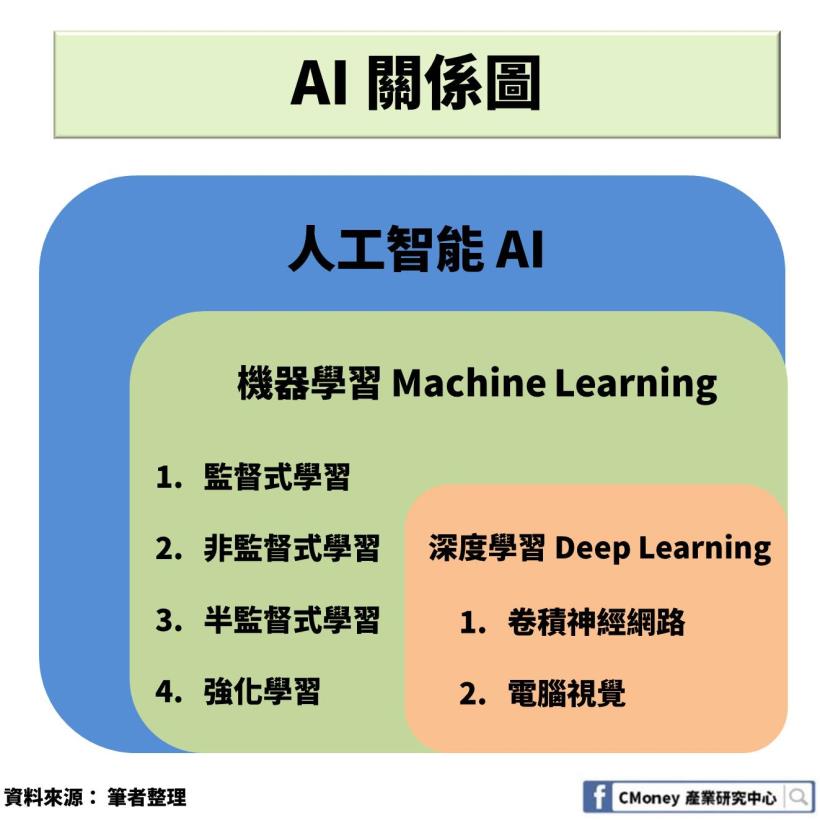
機器學習(Machine Learning)
機器學習是人工智能重要的子領域
也是一門橫跨多領域的學科技術
涉及機率論、統計學、逼近理論等等
由過往的資料分別建立演算法模型
再透過新的數據套入演算法中,由輸出結果判斷模型的成效
可以按照訓練樣本的特徵和反饋方式分為
監督式學習、非監督式學習、半監督式學習和強化式學習
監督式學習:
數據集是貼有標籤的(已知樣本的分類標準)
目標是透過建模的樣本中發現特徵間的關係
如預先給機器看 100 張貓和狗的圖案後
詢問機器下一張新的圖片是貓或狗
根據標籤類型可以分為
分類問題(Classification)和邏輯回歸問題(Logistic Regression)兩類
分類問題為預測數據所屬的非數值型類別(離散型變數)
如:垃圾郵件判斷、客戶流失預測等
而邏輯回歸問題則為預測數據的數值(連續型變數)
如房價預測、股價預測等
常見的演算法有支持向量機、KNN、決策樹等
無監督式學習:
顧名思義跟監督式學習相反
數據集沒有貼上標籤
依據相似樣本的特徵相關性歸類
在資料探勘初期是最好用的工具
對比監督式學習
可以大大減低繁瑣的人力成本,找出相似的規則
可運用在信用交易是否正常、保險金融等活動上
常見的演算法有 K-Means、主成分分析(PCA)、聚合式階層分群法(HAC)等
半監督式學習:
為監督式和非監督式結合的一種學習方法
對少部分資料貼標籤
電腦只要透過有被貼標籤的資料找出特徵
並與其它未貼標籤的資料進行分類
因為已經有辨識的依據
所以預測出來的結果通常比非監督式學習準確
常見的演算法有直推學習、歸納學習
強化式學習:
機器透過每一次與環境的互動來學習
取得最大化的預期效益
強化式學習的方式為樣本不貼任何標籤
但告訴它採取的哪一步是正確或錯誤
電腦根據反饋的好與壞,機器自行逐步修正
得到最終正確的結果
常見的演算法有馬可夫決策過程(MDP)、價值函數、Q-learning等
機器學習的應用比較
在監督式學習下
預先給機器 100 張貓與狗的照片後
詢問機器下一張照片是貓或狗;
在非監督式學習下
給機器看 100 張照片
但不告訴它哪張是貓或狗
機器直接將這 100 張照片做分群;
在半監督式學習下
給機器看 100 張片
其中的 10 張是貓與狗的照片
機器依據這 10 張貓與狗的照片判斷剩下的 90 張是貓或狗;
在強化式學習下
分別拿一張一張照片給機器看
直接判斷是貓或狗
機器從錯誤中不斷地改善並且修正學習
提升模型穩定性
上述的演算法模型沒有絕對的好與壞
需根據設計者針對不同的數據資料
選擇其中最適合的演算法模型
深度學習(Deep Learning)
近 30 年來在機器學習領域發展最為快速的
也是人工智能最重要的一個環節
其中又以卷積神經網路(CNN)廣為常用
透過模擬人類神經網絡的運作方式
自動依照位置的重要程度給予不同的加權數值
並將輸入的資料進行加權運算後輸出結果
觀察資料間的關聯性
相較於機器學習的優勢
深度學習的網絡間有如人類的神經元傳遞訊息
大幅提升資料傳遞間的穩定性
並有利於模型的快速學習
可從較少的變數情境下
快速判斷分類標準和提升模型的準確率
大幅減少資料的收集成本,使模型最佳化
深度學習被廣泛運用到不同的專業領域上
從視覺辨識、語音識別、自然語言處理到生物醫學等
都有卓越的表現
電腦視覺(Computer Vision)
屬深度學習的一種
透過攝影機和電腦代替人眼對目標進行辨識、追蹤和測量等
或是進一步進行圖像處理
轉換成更適合人類觀察的影像
而各類電腦視覺的任務皆須倚重機器學習和深度學習的技術來實現
這樣的技術被廣泛運用在自動駕駛、刷臉支付等生活上
使人類更靠近人工智能科技
小結
在晶片計算快速的進步下
加上大數據時代的來臨
有利於人工智能廣受各業界推崇
AI 技術目前已甚滲透至各行各業
如資安、金融、零售、醫療、教育等等
由政府的帶領下
各大企業積也積極佈局人工智能市場
IBM、Microsoft、Google、Facebook 等大公司已洞察先機
由此可想而知
不具備 AI 思維的企業是沒有未來的
不具備 AI 思維的人才是沒有高度的
下一篇文章將深入探討
人工智能未來的應用層面
以及哪些企業將成熟的 AI 技術導入
將引領未來 5-10 年的人工智能世代
請大家持續敬請期待
如果你喜歡這篇文章
如果你想跟我一起學投資
歡迎追蹤我的粉絲團
不定期分享個股、產業研究報告
⇩ ⇩ ⇩ ⇩ ⇩ ⇩ ⇩ ⇩ ⇩



